
Когда говорим «секьюрная архитектура веб‑приложений», у многих в голове всплывают абстрактные диаграммы и скучные стандарты. На деле это очень приземлённая вещь: набор решений, из‑за которых ваш сервис либо спокойно переживает атаки, либо ложится при первой же попытке SQL‑инъекции. Давайте разберёмся по‑человечески, без магии и при этом не теряя глубины.
> Важное уточнение: мои знания обновлены до конца 2024 года. Статистика за 2025–2026 годы пока недоступна, поэтому я опираюсь на данные 2021–2023 и заодно отмечаю тренды, которые с высокой вероятностью продолжаются.
—
Что мы вообще защищаем и от кого
Архитектура безопасности веб‑приложения — это не только «поставить WAF и не париться». Это совокупность решений: как разделены сервисы, как хранятся секреты, кто к чему имеет доступ, где логируются события и как вы будете реагировать на инцидент.
За последние годы цифры вполне отрезвляющие:
— По отчёту Verizon DBIR 2023, около 74% взломов так или иначе связаны с человеческим фактором: фишинг, слабые пароли, ошибки конфигурации.
— OWASP в 2021–2023 годах отмечает, что инъекции и проблемы с аутентификацией по‑прежнему входят в топ‑угроз для веб‑приложений; костыли в коде всё ещё опаснее экзотических 0‑day.
— По данным IBM Cost of a Data Breach 2023, средняя стоимость утечки данных выросла до примерно 4,45 млн долларов, причём у компаний с «secure by design»‑подходом ущерб был примерно на 30–40% ниже.
Иначе говоря, взламывают не потому, что у вас нет модной AI‑защиты, а потому что архитектура и процессы оставляют много лазеек.
—
Ключевые принципы секьюрной архитектуры
Минимальные привилегии и разделение обязанностей
Долгие годы статистика показывает одно и то же: чем больше у одного компонента или аккаунта прав, тем громче последствия взлома. Уход от монолита к микросервисам сам по себе не спасает, если каждый сервис может «всё и везде».
Старайтесь, чтобы:
— у сервиса были права только на свои таблицы/очереди;
— админские действия отделялись от пользовательских;
— для DevOps, разработчиков и аналитиков существовали разные роли и доступы.
Коротко: всё, что может быть ограничено по правам и зонам, должно быть ограничено.
«Secure by design», а не «прикрутим потом»
Внедрение secure by design архитектуры веб приложений означает, что вы закладываете безопасность в дизайн так же, как производительность и удобство. Не «потом как‑нибудь добавим токены», а сразу: где храним секреты, как шифруем, как проверяем входные данные, как строим SSO.
Такие системы не становятся «неуязвимыми», но их намного сложнее проломить случайной уязвимостью из Stack Overflow.
—
Необходимые инструменты: чем реально пользуются команды
Базовый технологический набор
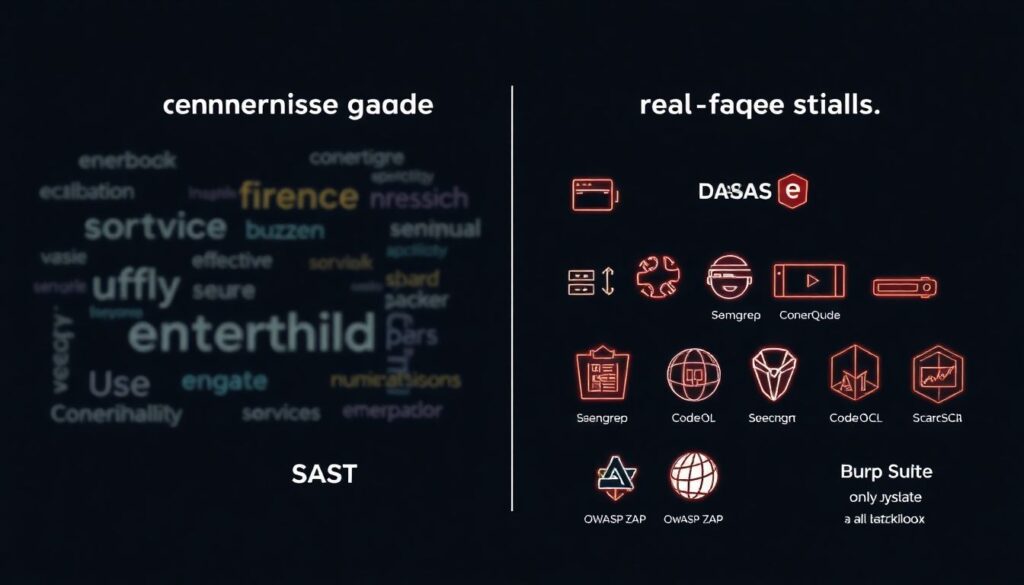
Вместо абстрактных «решений класса enterprise», давайте по сути. Для разработки безопасных веб‑приложений пригодится такой стек:
— SAST‑сканеры (Semgrep, SonarQube, CodeQL) — ищут уязвимости прямо в коде.
— DAST‑сканеры (OWASP ZAP, Burp Suite) — сканируют уже работающий сервис как «чёрный ящик».
— Секрет‑сканеры (TruffleHog, Gitleaks) — ловят пароли и токены в репозиториях.
— Менеджеры секретов (HashiCorp Vault, AWS Secrets Manager, GCP Secret Manager) — хранилище ключей, токенов и паролей.
— WAF (Cloudflare, AWS WAF, NGINX с модулями) — фильтрация трафика, блокировка типовых атак.
— SIEM / логирование (ELK, Grafana Loki, Splunk) — сбор и анализ событий безопасности.
За 2021–2023 годы рынок этих инструментов стабильно рос двузначными темпами: по оценкам разных аналитических компаний, сегмент DevSecOps‑решений ежегодно прибавлял 15–20%, и это логично — атак больше, регуляций тоже.
Какие сервисы часто докупают
Даже если у вас сильная команда, в какой‑то момент придётся смотреть в сторону внешних партнёров:
— услуги аудита безопасности веб приложений, когда нужно независимое мнение и формальный отчёт;
— периодический пентест или red team‑упражнения для критичных систем;
— консалтинг по безопасности и архитектуре веб приложений, если вы строите сложную инфраструктуру и не хотите набивать шишки.
Так получается здоровая комбинация: внутренняя команда держит ежедневную гигиену, а внешние специалисты находят слепые зоны.
—
Поэтапный процесс: как строить секьюрную архитектуру с нуля
Этап 1. Модель угроз и контекст бизнеса
Делать «военный бункер» для лендинга бессмысленно, а для финтех‑сервиса — наоборот опасно экономить. Начинаем с вопроса: кто и зачем может атаковать ваш сервис.
Полезно:
— описать бизнес‑процессы: где деньги, где персональные данные, где конфиденциальная логика;
— нарисовать data flow diagrams — как ходят данные между фронтом, бэком, БД, внешними API;
— для каждой точки входа (логин, загрузка файлов, вебхуки, админка) выписать потенциальные угрозы: инъекции, XSS, SSRF, захват сессии, brute force.
В 2021–2023 годах в отчётах Microsoft и Google по облачной безопасности регулярно фигурирует одна и та же мысль: компании, которые делают формальную модель угроз, уменьшают число серьёзных инцидентов примерно на 25–30%. Просто потому, что перестают закрывать глаза на очевидные дыры.
Этап 2. Выбор архитектурных паттернов
Когда понятны угрозы, выбираем подходящие паттерны. Вот несколько рабочих, а не книжных:
— Зональная архитектура (tiering): DMZ, внутренняя зона, зона данных; между ними — жёсткие ACL и отдельные сети.
— Zero Trust / «never trust, always verify»: каждое обращение между сервисами проходит аутентификацию и авторизацию, даже внутри кластера.
— Backend‑for‑Frontend (BFF): отдельный бэкенд для каждого типа клиента (web, mobile), чтобы не раздувать универсальный API и не открывать лишнее.
— Segregation of Duties / Separation of Concerns: раздельные сервисы для аутентификации, биллинга, уведомлений, аналитики, чтобы компрометация одного не рушила всё.
Короткий ориентир: если ваш диаграмма архитектуры помещается на салфетку и состоит из «фронт — бэк — база», защиты там, скорее всего, мало.
Этап 3. Контроль доступа и идентичность
Ошибки в аутентификации и авторизации остаются в числе топ‑проблем OWASP последние годы. В 2022–2023 годах до 24–30% критичных уязвимостей в веб‑приложениях относились именно к управлению доступом.
На уровне архитектуры это означает:
— использовать устоявшиеся протоколы (OAuth 2.1, OIDC, SAML), а не самописные токены на куках без флага Secure;
— централизовать auth‑сервис и не дублировать логику ролей в каждом микросервисе;
— делать авторизацию на стороне бэкенда для каждого запроса, а не надеяться на «скрытые кнопки» во фронтенде.
Коротко: аутентификация должна быть скучной, предсказуемой и стандартизированной, а не креативной.
Этап 4. Безопасная работа с данными
Тут всё про шифрование, маскирование и изоляцию.
— Шифруем данные «на диске» (at rest) и «на проводе» (in transit).
— Секреты храним только в менеджере секретов, а не в `config.yml.example`.
— Для чувствительных полей (номера карт, документы, медданные) используем токенизацию или псевдонимизацию.
По исследованиям (например, Ponemon Institute, 2023), компании с повсеместным шифрованием данных снижали фактический ущерб от утечки примерно на 20–30%, просто потому что украденное оказывалось малополезным без ключей.
Этап 5. DevSecOps: безопасность как часть пайплайна
Разработка безопасных веб приложений под ключ сегодня почти всегда подразумевает DevSecOps‑подход. Не «перед релизом дадим код тестировщикам безопасности», а проверки на всех этапах:
— На этапе коммита — линтеры, secret‑сканеры.
— В CI — SAST и базовый DAST.
— Перед релизом — ручное ревью критичных кусков, проверка миграций БД.
— После релиза — мониторинг, алерты, регулярные пентесты.
По оценке GitLab DevSecOps Survey 2022–2023, команды, которые внедрили автоматизированные проверки безопасности в CI/CD, снижали количество уязвимостей, попадающих в прод, примерно на 50%.
Этап 6. Пентесты, аудит и пересмотр архитектуры
Даже идеальная архитектура устаревает. Новые фреймворки, новые уязвимости, смена бизнес‑логики — всё это ломает изначальные предположения.
Для этого нужны:
— регулярные услуги аудита безопасности веб приложений — чтобы смотреть на систему свежим взглядом;
— внешний пентест хотя бы раз в год, и особенно перед большими релизами;
— пересмотр прав и зон сетевой сегментации, когда сервисы разрастаются.
Здесь неизбежный вопрос: пентест и проверка защиты веб приложения цена. По отчётам некоторых консалтинговых компаний за 2022–2023 годы, разброс огромный: от нескольких тысяч долларов для типового SaaS до десятков тысяч для сложных финтех‑систем. Но почти все исследования бьют в одну точку: стоимость пентеста на порядки ниже стоимости серьёзного инцидента.
—
Паттерны и практики, которые реально работают
1. Defense in Depth: многослойная защита
Идея простая: пусть злоумышленнику придётся пройти не одну, а несколько линий обороны.
Рабочие слои:
— Ввод на фронтенде — валидация и маскирование.
— API‑шлюз — rate limiting, аутентификация, базовые проверки.
— Бэкенд — строгая валидация данных, параметризованные запросы, защита от инъекций.
— БД — ограниченные роли, row level security (где возможно).
— Сеть — отдельные подсети, ограничение межсервисного трафика.
— Логи и мониторинг — обнаружение аномальной активности.
Коротко: если один слой дал сбой, остальные не дают атаке легко дойти до ядра.
2. Безопасный по умолчанию (Secure Defaults)
Большая часть инцидентов в 2021–2023 годах была банальной: открытые S3‑бакеты, дебаг‑панели в проде, админка без MFA.
Хорошая архитектура исходит из того, что:
— новые сервисы получают минимальные права по умолчанию;
— доступ в админку закрыт снаружи, пока вы явно не откроете;
— все критичные операции требуют MFA или повышенного уровня доверия.
Это кажется мелочью, но статистика показывает: простые настройки по умолчанию блокируют огромное количество массовых автоматизированных атак.
3. Наблюдаемость и готовность к инцидентам
Если у вас нет нормальных логов, алертов и плана действий, то даже небольшая проблема превращается в затяжной кризис.
Полезный минимум:
— централизованный сбор логов (аутентификация, авторизация, ошибки, административные действия);
— оповещения по: множественным неудачным логинам, резкому росту 5xx, аномальному трафику по редким эндпоинтам;
— заранее прописанный incident response plan: кто отвечает, какие шаги, какие системы отключаем, что говорим пользователям и регуляторам.
По отчётам IBM и ENISA за 2021–2023 годы, компании с отлаженной процедурой реагирования сокращали среднее время обнаружения инцидента с месяцев до недель или даже дней, что уменьшало ущерб на сотни тысяч долларов.
—
Типовые грабли и устранение неполадок
Проблема 1. «Система медленнее после включения безопасности»
Часто после внедрения WAF, дополнительной валидации и логирования разработчики жалуются: «всё тормозит».
Разруливать можно так:
— вынести тяжёлые проверки (антивирус для файлов, дополнительные сканы) в асинхронные очереди;
— включить кэширование там, где это безопасно (ответы для статичных страниц, публичный контент);
— измерять не «кажется медленно», а реальные метрики: p95/p99 latency, время работы конкретных middleware.
Небольшой оверхед в пределах 5–10% по времени ответа нормален и укладывается в наблюдаемые по рынку показатели после внедрения дополнительных слоёв защиты.
Проблема 2. «Ложные срабатывания и заблокированные пользователи»
Чем агрессивнее правила защиты, тем выше риск заблокировать честных пользователей.
Шаги по настройке:
— сначала включайте новые правила в режиме мониторинга: логировать, но не блокировать;
— собирайте статистику: какие запросы чаще всего помечаются подозрительными, откуда и при каких действиях;
— только после этого постепенно переводите правила в «режим блокировки».
По статистике провайдеров WAF за 2022–2023 годы, итерационный подход (наблюдение → настройка → блокировка) позволяет снизить количество ложных срабатываний в несколько раз без ослабления реальной защиты.
Проблема 3. «Секреты всё равно всплывают в коде»
Даже с менеджером секретов разработчики по привычке могут прописывать токены напрямую в `.env` и коммитить их в репозиторий.
Для устранения:
— включите secret‑сканеры на уровне pre‑commit и CI;
— заведите регламент: при утечке секрета он не «удаляется из кода», а ревокается и перевыпускается;
— проведите короткое обучение команды, как правильно работать с конфигурацией.
Практика компаний в 2021–2023 годах показывает, что после введения таких правил число «засвеченных» секретов в открытых репозиториях и логах падает на порядок.
Проблема 4. «Никто не понимает текущую архитектуру»
Со временем сервис обрастает микросервисами, сторонними интеграциями, временными заглушками. В итоге никто не может точно сказать, где какие данные ходят и что вообще нужно защищать.
Как лечить:
— провести инвентаризацию сервисов и данных: что есть, кто владелец, какие зависимости;
— нарисовать актуальные диаграммы (хотя бы на уровне основных зон и потоков данных);
— привлечь внешний консалтинг по безопасности и архитектуре веб приложений, если внутренним силам тяжело «разгрести» исторические наслоения.
После таких ревизий часто всплывают открытые админки, старые тестовые окружения и забытые S3‑бакеты, которые годами ждали своего часа.
—
Где граница между «сделать самим» и «отдать на аутсорс»
Разработка безопасных веб приложений под ключ — это не обязанность одной роли. Нормальная картина выглядит так:
— внутренняя команда: проектирует архитектуру, внедряет secure by design‑подход, настраивает DevSecOps, следит за ежедневной «гигиеной»;
— внешние специалисты: делают периодические аудиты, пентесты, помогают с выбором архитектурных решений и инструментов.
Когда вы доходите до сложных кейсов (финтех, здравоохранение, госуслуги), имеет смысл комбинировать: постоянная внутренняя экспертиза + регулярный внешний аудит и пересмотр решений.
—
Вместо вывода

За последние три года тренд очевиден: атак становится больше, они автоматизируются и становятся дешевле для злоумышленников. При этом икону из очередного «серебряного пули» не спасёт, если архитектура приложения рыхлая, а процессы безопасности — набор разрозненных правил.
Рабочая стратегия строится вокруг нескольких идей:
— думать об угрозах с самого начала, а не после релиза;
— строить архитектуру по принципам secure by design и defense in depth;
— автоматизировать проверки безопасности в CI/CD;
— регулярно проводить аудит и пентесты, а не ждать инцидента;
— уметь быстро диагностировать и устранять неполадки, а не искать виноватого.
Если относиться к секьюрности не как к «обязательной бюрократии», а как к части инженерной культуры, то архитектура веб‑приложения превращается из источника постоянного риска в конкурентное преимущество: пользователи вам доверяют, регуляторы меньше задают вопросов, а ночной сон команды становится заметно спокойнее.