
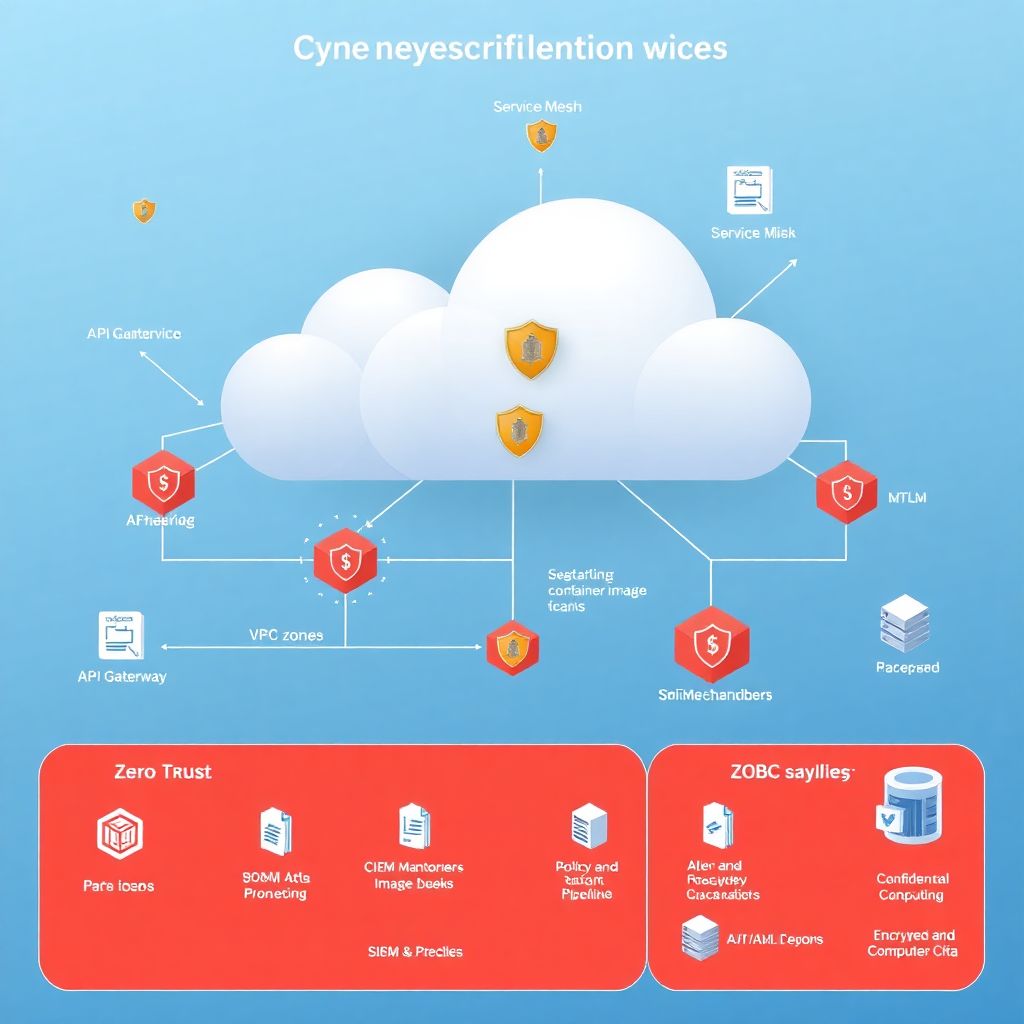
Зачем вообще думать о безопасности микросервисов в облаке в 2026 году
Если пару лет назад многие радовались, что «микросервисы в Kubernetes» уже сами по себе прогресс, то в 2026‑м это звучит наивно. Сейчас облака стали не только стандартом, но и основной целью атак: цепочки поставки ПО, уязвимые контейнеры, скомпрометированные CI/CD, утечки через третьи сервисы — всё это уже рутина, а не страшилки с конференций. Поэтому безопасная архитектура микросервисов в облаке — это не «опция для банков», а базовая гигиена даже для среднего стартапа. Иначе вы однажды проснётесь не с ростом MRR, а с инцидентом, который сжёг весь квартальный бюджет на юристов и форензику.
Шаг 1. Начать с модели угроз, а не с выбора фреймворка
Первая ошибка, которую делают почти все: начинают с технологий. «Возьмём Kubernetes, Istio, API Gateway — и дальше по накатанной». В результате появляется сложная система, но не очевидно, от кого и от чего вы защищаетесь. Вместо этого сядьте и нарисуйте, кто может хотеть вас атаковать, где проходят деньги и чувствительные данные, какие интеграции с внешними системами у вас уже есть и планируются. Это не академическое упражнение — хороший набросок модели угроз сэкономит месяцы тупиковых внедрений и снизит вероятность, что вы защитите второстепенный сервис, забыв о единственной точке входа в биллинг.
Как это выглядит на практике
Опишите бизнес‑процессы крупными мазками: откуда приходят пользователи, какие внешние API называете, где храните персональные или финансовые данные, какие администраторы и подрядчики имеют доступ. Затем определите критические пути: всё, что ведёт к деньгам, данным клиентов и управлению инфраструктурой, пометьте как «красную зону». Далее зафиксируйте базовые сценарии атак: кража токенов доступа, компрометация CI/CD, эксплуатации уязвимостей в публичном API, злоупотребление правами внутри облака. Только после этого переходите к конкретным решениям и выбору облачного провайдера — иначе вы будете латать дыры по ощущениям, а не по реальным рискам.
Шаг 2. Выбрать облако и разделить ответственность по‑взрослому
В 2026 году крупные облака предлагают тонну безопасных сервисов «из коробки»: управляемые базы, секрет‑менеджеры, встроенный WAF, Key Management Service, сервисные аккаунты с минимальными правами. Но до сих пор многие команды не понимают, где зона ответственности облака заканчивается и где начинается их собственная. Факт в том, что облако отвечает за безопасность инфраструктуры, а вы — за безопасность ваших микросервисов, конфигураций, сетей и секретов. Никакие «галочки» в консоли провайдера не спасут, если доступ к продакшену выдаётся по просьбе в чате, а секреты лежат в config‑map’ах в открытом виде.
Что важно проверить при выборе провайдера
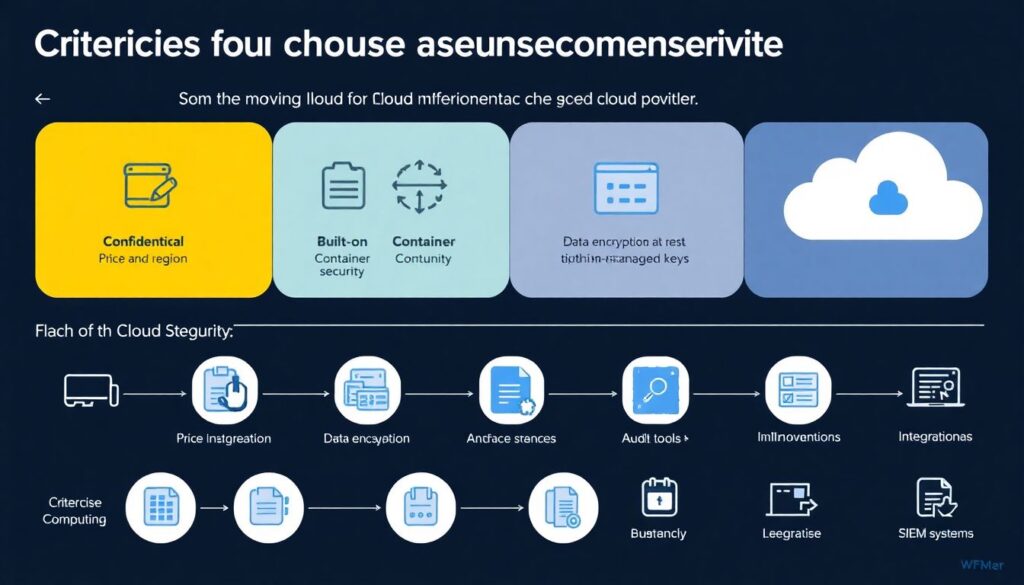
Смотрите не только на цену и регион, но и на зрелость их облачных средств безопасности: поддержка конфиденциальных вычислений (confidential computing), встроенная защита контейнеров, возможность шифрования «на покое» и в полёте с собственными ключами, наличие инструментов аудита и интеграции с SIEM. Не стесняйтесь задавать неудобные вопросы саппорту: как быстро они предоставляют логирование инцидентов, какие отчёты по соответствию стандартам (SOC 2, ISO 27001, PCI DSS) есть, как реализованы аппарты для ключей (HSM). Это особенно актуально, если вы рассматриваете услуги по построению микросервисной архитектуры в облаке от внешних интеграторов: спросите, какие именно возможности провайдера они используют и как делят зоны ответственности.
Шаг 3. Строим Zero Trust как основу микросервисной безопасности
Архитектура «мы все в одном доверенном кластере, а значит можно без шифрования и строгих политик» в 2026‑м фактически мертва. Zero Trust — это не модное слово, а признание реальности: внутри вашей сети тоже могут сидеть злоумышленники, скомпрометированные сервисы и неосторожные админы. Каждому запросу и каждому компоненту приходится относиться как к потенциально враждебному. Это звучит строго, но в микросервисном мире как раз удобно: каждая служба и каждый пользователь получают минимальный набор прав, а коммуникации шифруются и логируются без исключений.
Основные принципы Zero Trust в микросервисах
Не доверять сетям по умолчанию, идентифицировать не только пользователей, но и сервисы, шифровать почти всё, что движется между микросервисами, и включать явные политики доступа вместо допущений по молчанию. В качестве технологической базы всё чаще используют сервис‑меши (Istio, Linkerd, современные managed‑решения от облаков), которые умеют реализовывать mTLS между сервисами, централизованный контроль политик и единое наблюдение за трафиком. Для новичков это может показаться усложнением, но если заложить Zero Trust с самого начала, потом значительно проще масштабировать систему без боли и глобальных переделок.
Шаг 4. Правильно проектировать границы микросервисов и API
Безопасность часто ломается не из‑за хакеров, а из‑за хаотичного разрезания монолита на микросервисы. Сервис, который изначально должен был заниматься только профилем пользователя, вдруг начинает выдавать чувствительные платёжные данные, потому что «так быстрее» и «надо успеть к релизу». Результат — избыточная поверхность атаки и постоянные костыли в виде фильтров на API‑шлюзе. Намного надёжнее изначально проектировать границы сервисов исходя не только из бизнес‑логики, но и из принципов минимизации данных и прав доступа; это снижает не только риск утечек, но и сложность соблюдения регуляторных требований.
Современный подход к проектированию API
Старайтесь, чтобы каждый микросервис оперировал только теми полями и событиями, которые ему действительно нужны, а публичные API были максимально узкими и чётко документированными. В 2026‑м уже стандарт де‑факто — описывать API в формате OpenAPI/AsyncAPI и генерировать из них не только клиенты, но и политики безопасности: допустимые схемы запросов, лимиты, правила авторизации. Новичкам полезно сразу привыкнуть: любая «быстрая» временная лазейка в API почти гарантированно живёт годами и становится источником уязвимостей, так что лучше потратить время на аккуратное проектирование на старте.
Шаг 5. Построить надёжный API Gateway и контроль доступа
API‑шлюз — это не просто маршрутизатор, а фактически «пограничник» между внешним миром и вашими микросервисами. Именно здесь вы реализуете аутентификацию пользователей и клиентов, rate limiting, базовый WAF, проверку токенов и централизованное логирование. В 2026 году в продакшене всё чаще используют комбинацию из API‑шлюза и сервис‑меша: первый отвечает за внешнюю грань, второй — за внутренние коммуникации. Важно не пытаться «запихнуть» всю логику в API‑шлюз; он должен заниматься безопасным входом в вашу систему, а не браться за бизнес‑правила и сложные оркестрации.
Современные тренды в контроле доступа
Сместился акцент от «ролей в коде» к «политикам как коду» (policy‑as‑code). Вместо того чтобы прописывать условия доступа прямо в микросервисах, правила описывают в декларативном виде (например, через Open Policy Agent или аналогичные движки) и хранят в репозиториях, проходят через code‑review и тестирование. Это не только упрощает аудит, но и снижает риск рассинхронизации логики по разным сервисам. Новичкам важно не увлечься «универсальными» решениями и начать с простого RBAC, постепенно добавляя атрибут‑based‑доступ, чтобы не утонуть в сложных правилах, которые никто не может объяснить.
Шаг 6. Секреты, токены и ключи: не класть всё в один ящик
До сих пор встречаются проекты, где доступы к базам и внешним API лежат в переменных окружения, а иногда и прямо в коде. В микросервисной архитектуре это превращается в минное поле: чем больше сервисов, тем больше мест, где можно случайно засветить секрет. В 2026‑м в продакшене считается нормой использовать выделенный менеджер секретов облака, ротацию ключей по расписанию, шифрование конфигураций и разделение секретов по средам. Это не прихоть безопасников, а способ выжить, когда разработчики и DevOps постоянно что‑то деплоят и изменяют.
Практические советы по управлению секретами
Не придумывайте свои велосипеды: используйте нативные секрет‑менеджеры провайдера или проверенные решения, которые хорошо интегрируются с Kubernetes и CI/CD. Настройте автоматическую ротацию ключей, особенно для сервисных аккаунтов и токенов доступа к внешним платёжным системам. Для новичков важно: никогда не передавайте секреты через мессенджеры и не храните «дублирующие» копии в личных заметках. Как только вы начнёте автоматизировать управление секретами, обычная выгрузка репозитория уже не приведёт к катастрофе, потому что даже украденные токены скоро перестанут работать.
Шаг 7. Кластеры и сети: минимум входов, максимум наблюдаемости
Многие по инерции продолжают строить плоскую сетку: один кластер или одна VPC, множество микросервисов и немного сетевых политик «на потом». В реальности современная безопасная архитектура микросервисов в облаке предполагает сегментацию: разделение по окружениям, продуктовым линиям, критичности и типам данных. Чем меньше общих «перемычек» между зонами, тем труднее нарушителю перемещаться внутри системы после первого взлома. При этом важно не увлечься микросегментацией, чтобы не утонуть в управлении, а найти разумный баланс по зрелости вашей команды.
Новые возможности сетевой безопасности в 2026
Растёт использование eBPF‑решений для глубокого наблюдения за сетевым трафиком и поведения контейнеров без тяжёлых агентов и прокси. Облака предлагают управляемые сервис‑меши и встроенные Network Policies по умолчанию для Kubernetes. При этом главная ошибка новичков — включить всё подряд, не понимая, что именно и чем управляет; итог — случайные даунтаймы и обход политик «вручную», чтобы быстрее починить прод. Лучше идти по шагам: сначала закрыть внешний периметр и явно открыть только нужные порты и протоколы, потом постепенно добавлять политики для внутренних сервисов, проверяя каждое изменение в стейджинге.
Шаг 8. Цепочка поставки: защищаем не только продакшен
В 2026 году большинство серьёзных атак на облака и микросервисы идёт не напрямую через продакшен, а через цепочку поставки: уязвимости в зависимостях, скомпрометированные контейнерные образы, вредоносные пакеты в реестрах, взломанные CI/CD‑серверы. Поэтому защищать только рантайм уже поздно; нужно смотреть на весь путь от написания кода до выката в кластер. В противном случае вы будете лихо ставить патчи и политики в проде, но туда спокойно попадёт «троян» внутри вашей же сборочной логики.
Современные практики безопасности supply chain
Сейчас стандартом становится использование SBOM (Software Bill of Materials) — «ведомости ингредиентов» для каждого артефакта: какие библиотеки и версии входят в ваш сервис. Плюс — обязательное сканирование зависимостей и образов перед деплоем, подписание контейнеров и политик допуска образов в кластере (only signed images). Услуги вроде консалтинг по безопасности микросервисов в облачной среде всё чаще строятся вокруг того, чтобы вы не просто внедрили сканер уязвимостей, а настроили процесс: кто реагирует, как быстро, что считается блокирующим для релиза, а где допустим технический долг с понятными сроками.
Шаг 9. Мониторинг, аудит и реагирование как повседневная рутина
«Мы всё логируем» — не значит «мы понимаем, что происходит». В микросервисной архитектуре количество логов, метрик и трассировок растёт лавинообразно, и без систематического подхода вы тонете в шуме. Для безопасности это смертельно: подозрительная активность теряется среди тысяч обычных ошибок. Гораздо полезнее иметь продуманную схему: какие события считать важными, как они стекаются в хранилище, какие алерты настроены и кто именно за них отвечает по расписанию. Без людей и процессов даже самый навороченный SIEM не поможет.
Тренд 2026: умная корреляция и AI‑подсказки
Облачные провайдеры и крупные платформы наблюдаемости активно используют машинное обучение и поведенческий анализ, чтобы распознавать аномалии: неожиданные паттерны логинов, всплески запросов к чувствительным API, нетипичные маршруты трафика. Ваша задача — не «включить волшебный тумблер ИИ», а правильно настроить источники сигналов, нормализацию событий и пороги триггеров. Не забывайте про аудит безопасности микросервисной архитектуры в облаке: периодический разбор логов, прав доступа и конфигураций независимыми специалистами нередко находит тихие, но очень неприятные ошибки, которые команда перестала замечать.
Шаг 10. Работа с людьми и процессами: DevSecOps по‑настоящему
Чисто техническая защита без участия людей быстро превращается в сказку. Какой бы продвинутый сервис‑меш и WAF вы ни настроили, если разработчики продолжают заливать секреты в репозитории, а менеджеры давят на «релиз любой ценой», инциденты неизбежны. Современный DevSecOps — это когда безопасность встроена в ежедневный рабочий процесс: чек‑листы в PR, автоматические проверки в CI, обязательные «security gates» на критических ветках, понятные плейбуки на случай утечек. Важно, чтобы команда видела в этих практиках помощь, а не тормоз, иначе начнётся тихий саботаж и поиск обходных путей.
Как объяснить безопасность новичкам и не убить мотивацию
Не грузите начинающих инженеров тоннами политик и страшных историй. Лучше дайте им простые правила: не хранить секреты в коде, не открывать доступы «навсегда», всегда проверять, какой объём данных уходит наружу, и спрашивать, если не уверены. Постепенно подключайте их к разбору реальных инцидентов и учите смотреть на системы глазами атакующего: что будет, если я украду этот токен, если смогу вызвать этот внутренний API, если получу доступ к бекапам? Такой подход выращивает культуру ответственности намного лучше, чем формальные тренинги раз в год.
Типичные ошибки при построении безопасной микросервисной архитектуры
Самое распространённое — верить, что «облако всё сделает за нас». Провайдер даёт хорошие инструменты, но не берёт на себя проектирование ваших сетей, микросервисов и процессов доступа. Вторая частая ошибка — перегрузить архитектуру сложными решениями (mesh, сложный IAM, десятки сред) на старте и не иметь ресурсов их поддерживать; в итоге политики снимают «временно», а временно, как мы знаем, часто означает «навсегда». Третья проблема — отсутствие ясных границ владения: никто не отвечает целиком за безопасность какого‑то домена, и все считают, что это чья‑то чужая зона. В результате дырки обнаруживаются только при инцидентах или внешних проверках.
Как избежать этих ловушек
Двигайтесь итеративно: определили приоритетные риски, закрыли их минимальным набором инструментов, отладили процесс, только после этого добавляйте следующее звено. Не гонитесь за «идеальной» моделью: важнее иметь рабочий и понятный подход, чем набор модных технологий. И обязательно назначайте владельцев (owners) за сервисы, данные и процессы безопасности: каждый должен понимать, за какой кусок он отвечает. Если видите, что внутренняя компетенция не успевает за ростом системы, имеет смысл рассмотреть внедрение защищенной микросервисной архитектуры под ключ с участием внешних экспертов, но с условием, что знания и документация остаются в вашей команде, а не заперты у подрядчика.
Итоги: что важно запомнить в 2026 году
Микросервисы и облака давно перестали быть «модной новинкой» и превратились в рабочую норму, а атаки на них — в каждодневную практику. Успешные команды больше не воспринимают безопасность как надстройку поверх готового сервиса; они закладывают её в архитектуру, процессы доставки и культуру разработки. Ключевые идеи просты: осознать свои угрозы, использовать сильные стороны облака, внедрить Zero Trust, аккуратно проектировать API, контролировать цепочку поставки и не забывать про людей. Если вы будете развивать эти элементы шаг за шагом и не бояться периодически пересматривать свои решения, безопасная архитектура перестанет быть «головной болью», а станет обычной составляющей зрелой, устойчивой и масштабируемой микросервисной платформы.