
Понимаем, в чём вообще риск при работе с API в браузере
Когда мы тянем данные через API прямо из браузера, мы фактически отдаём часть внутренней логики приложения на обозрение пользователю и, заодно, злоумышленникам. Браузерный JavaScript нельзя спрятать полностью: любой человек с DevTools увидит запросы, эндпоинты, заголовки и иногда даже внутренние идентификаторы. Поэтому обучение безопасной работе с api в браузере — это не «какая‑то параноидальная опция», а базовая гигиена для любого фронтенд‑разработчика. Нужно сразу принять простую мысль: всё, что попадает в браузер, считается скомпрометированным и не заслуживает доверия, включая токены, куки и даже локальное хранилище.
Основная проблема в том, что API исторически проектировались под сервер‑к‑серверу взаимодействие, где среда более контролируема. В браузере же у нас совсем другой игрок: пользовательская машина, на которой могут быть плагины, скрипты, вредоносные расширения, прокси‑инструменты и так далее. В такой среде безопасная работа с API превращается в постоянный баланс между удобством и минимизацией атакующей поверхности. Чем больше логики и полномочий вы отдаёте фронтенду, тем больше сценариев нужно продумать заранее и закрыть техническими и организационными мерами.
—
Браузер напрямую к API: когда это оправдано и чем рискуем
Плюсы прямых запросов из браузера
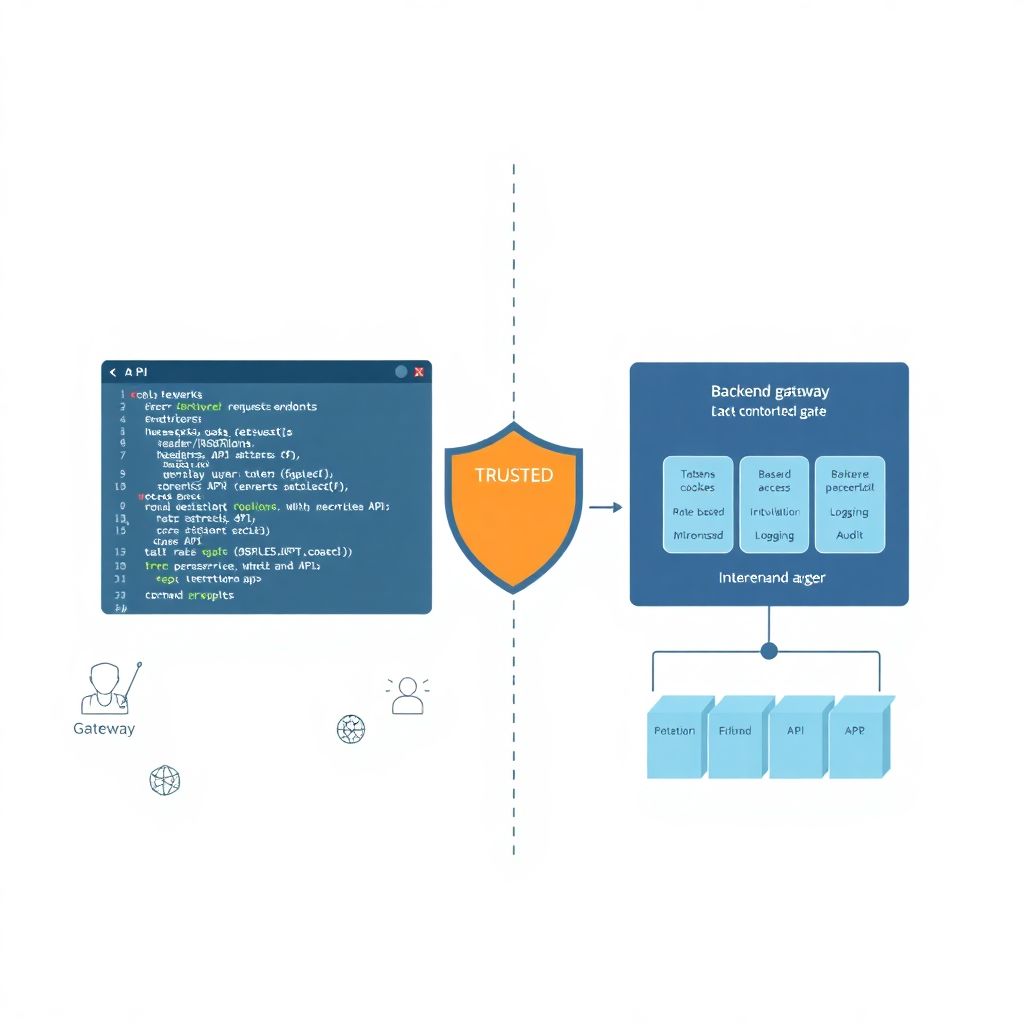
Самый очевидный и простой путь — вызывать API прямо из фронтенда: fetch/axios, JSON, CORS — и поехали. Это удобно, потому что уменьшает количество слоёв: клиент ходит сразу к API‑шлюзу, нет лишнего бэкенд‑прокси, проще масштабировать и логировать. Архитектура становится более предсказуемой, а разработчикам легче тестировать и отлаживать запросы, используя стандартные браузерные инструменты. Такой подход отлично заходит в микросервисной архитектуре с хорошо продуманным gateway, где каждый сервис зашит за единым фасадом и контролируется централизованно.
Однако тут важно понимать, что уменьшение количества промежуточных уровней параллельно сокращает и количество мест, где можно применить безопасные фильтры и проверочные механизмы. Когда браузер напрямую стучится в API, он становится полноценным участником протокола, и все потенциальные уязвимости конечной точки тут же выходят наружу. Успешный злоумышленник получает удобную площадку для автоматизации атак, потому что весь необходимый контекст уже виден и задокументирован самим приложением.
Минусы и типичные уязвимости прямого доступа
Классический набор проблем такого подхода: утечка токенов, чрезмерные права у клиента, отсутствие тонкой валидации на уровне бэкенда и опора на «честность» фронтенда. Многие новички наивно надеются, что если форма на странице не показывает какое‑то поле, то и злоумышленник не сможет его изменить. Но любой запрос можно перехватить и модифицировать. Поэтому любая серверная логика авторизации, проверки прав, лимитов или бизнес‑правил, завязанная исключительно на фронтенде, обречена. Кроме того, атаки типа XSS или внедрение вредоносного расширения в браузер пользовательского уровня сразу открывают злоумышленнику прямой доступ к тем же API, с теми же куками и заголовками, что и у легитимного пользователя, без необходимости ломать сам сервер.
—
Прокси‑слой между браузером и API: дополнительный щит или лишняя сложность
Что даёт бэкенд‑прокси с точки зрения безопасности
Альтернативный подход — не отпускать браузер напрямую к чувствительным эндпоинтам, а прятать их за собственным серверным слоем. В этом варианте браузер общается с вашим бэкендом, а уже бэкенд — с внешними или внутренними API. Такой паттерн позволяет скрыть реальные URL, использовать сервисные ключи и токены без их утечки на клиент, внедрить сложную авторизацию и аудит на безопасной стороне. Для многих компаний это ещё и удобный способ централизованно внедрять услуги по защите и тестированию api в браузере, так как единой точкой входа становится сам бэкенд‑шлюз, а не десяток разных конечных сервисов.
Прокси‑слой даёт возможность внедрить полноценный контроль доступа: роль‑бэйзед авторизацию, rate limiting, фильтрацию payload‑ов, логирование подозрительных паттернов поведения. В случае инцидента вы видите уже нормализованные запросы от фронтенда, а не десятки вариантов обращений к разным внешним сервисам, каждый из которых логирует по‑своему. Это упрощает расследование и позволяет быстрее вырабатывать сигнатуры для WAF или IDS/IPS систем, а также адаптировать политику безопасности без массовых правок кода на всех сторонах.
Какую цену платим за такой подход
Минус — дополнительная сложность и задержка. Прокси — это ещё один сервис, который нужно разрабатывать, поддерживать, масштабировать и мониторить. Он может сам стать узким местом или даже точкой отказа. Кроме того, усложняется трассировка: при ошибке нужно понять, где именно упал запрос — на фронте, в прокси или в конечном API. Некоторые разработчики пытаются перенести в прокси слишком много логики, превращая его в ещё один монолит, который трудно поддерживать. К тому же, если прокси сделан формально и не реализует реальной валидации и ограничения прав, он превращается лишь в дополнительный хоп в сети, не давая заметного прироста безопасности, а добавляя операционных проблем.
—
Токены, куки и локальное хранилище: как не хранить секреты «под ковриком»
Сравнение подходов: где держать аутентификационные данные
Когда доходишь до конкретики, начинаются споры: хранить токен в localStorage, sessionStorage, httpOnly‑куках или вообще использовать короткоживущие одноразовые токены? Каждый вариант компромиссный. LocalStorage удобен и прозрачен, но легко доступен из любого скрипта в контексте страницы, а значит — уязвим при XSS. Куки с флагом httpOnly защищены от чтения через JavaScript, но автоматически отправляются на каждый запрос к домену, что усложняет гибкий контроль и поднимает вопросы о защите от CSRF. SessionStorage немного безопаснее, чем localStorage, потому что живёт в рамках вкладки, но основная проблема при XSS никуда не исчезает, так как злоумышленник всё равно сможет к нему обратиться через подменённый скрипт.
Разговорный совет, но с технической подоплёкой: если вы сомневаетесь, выбирайте httpOnly‑куки плюс строгую защиту от CSRF и максимально короткий срок жизни сессии. А для особо критичных операций применяйте дополнительные одноразовые подтверждения или step‑up аутентификацию. Такой гибридный подход требует больше усилий на серверной стороне, но снижает риск массовой компрометации при единичной уязвимости на фронте. Важно помнить, что как бы красиво ни выглядел фронтенд‑код, любые хранимые в приложении секреты в итоге оказываются доступными при достаточной мотивации атакующего.
—
Пошаговый подход к проектированию безопасного API во фронтенде
Шаг 1. Жёстко разделяем доверенные и недоверенные зоны
Первый шаг — в голове и в архитектуре: чётко разделить то, что можно отдать в браузер, и то, что там вообще не должно появляться. Никакие секреты, приватные ключи, сервисные токены, внутренние идентификаторы инфраструктуры и подробные диагностические сообщения не имеют права жить в JavaScript‑коде или конфиге, который отдаётся клиенту. Всё, что загружается в браузер, надо считать потенциально доступным для чтения третьей стороной. Поэтому бизнес‑правила, связанные с финансовыми операциями, изменением критичных данных или администрированием системы, надо реализовывать на сервере, а фронтенд должен быть лишь интерфейсом для формирования запросов.
Это звучит очевидно, но на практике многие команды проходят через одинаковые ошибки: временные ключи «для теста», оставленные в коде, API‑ключи для внешних сервисов прямо в фронтенд‑конфиге, детализированные сообщения об ошибках с трейсами, попадающие в консоль браузера. Со временем всё это накапливается и превращается в интересный набор подсказок для атакующего. Поэтому с самого начала закладывайте в архитектуру принцип: «минимум привилегий на клиенте, максимум проверок на сервере».
Шаг 2. Ограничиваем полномочия каждого запроса
Второй шаг — принцип минимально необходимых разрешений для каждого API‑запроса, который вы позволяете отправлять из браузера. Не давайте одному токену возможность делать всё подряд: чтение, запись, удаление, администрирование и так далее. Лучше разделить полномочия по типу операций и по ролям пользователей. Например, токен, который используется для отображения публичной информации, не должен обладать правами на модификацию или удаление этих данных. Там, где это возможно, используйте scope‑ы, claim‑ы и другие механизмы ограничения доступа на уровне JWT или аналогичных схем.
Новичкам часто кажется, что тонкая настройка прав — лишняя бюрократия, особенно на раннем этапе проекта. Но как только появляется первый внешний пользователь, а затем и интеграции с другими системами, вернуть контроль становится намного сложнее, чем заложить его сразу. Грамотно продуманная модель разрешений снижает потенциальный ущерб в случае утечки конкретного токена: злоумышленник сможет сделать меньше вредных действий и быстрее будет замечен аномалиями в логах и системах мониторинга.
Шаг 3. Настраиваем CORS и изоляцию происхождений
Третий шаг — аккуратно настроенный CORS. Многие разработчики, устав бороться с ошибками типа «No ‘Access‑Control‑Allow‑Origin’ header», попросту включают `Access-Control-Allow-Origin: *` на сервере, перекладывая заботу о безопасности на приложение. Это практически открытая дверь для злоупотреблений, особенно когда API содержит персональные или чувствительные данные. Лучше тратить время на чёткий список доверенных доменов, использовать строгий список методов и заголовков, а для критичных операций реализовывать дополнительные проверки на стороне сервера, например, по токенам и контексту сессии.
Не забывайте про происхождение (origin). Разные домены, порты, протоколы — это разные контексты безопасности. Правильная настройка CORS в связке с cookies и токенами — основа, без которой любые верхнеуровневые механизмы будут уязвимы. Важно не только перечислить доверенные источники, но и периодически пересматривать этот список: удалять устаревшие домены, тестовые стенды, временные поддомены. Чем короче и свежее список доверия, тем меньше возможности у злоумышленника использовать забытые лазейки.
Шаг 4. Валидируем всё, что приходит с клиента
Четвёртый шаг – тот, о котором знают все, но нарушают регулярно: валидация входных данных на серверной стороне, даже если на фронтенде уже сделана идеальная проверка. Бразуерную валидацию легко обойти: достаточно вручную отправить запрос через curl, Postman или специализированный скрипт. Сервер должен считать все данные подозрительными, и каждое поле — независимо валидировать по типу, длине, формату и допустимым значениям. Особенно это критично для полей, которые участвуют в построении запросов к базам данных, файловой системе или внешним сервисам.
Типичные ошибки новичков — доверие к полям, которые «нельзя изменить через обычный интерфейс», например, скрытым инпутам или неотображаемым полям формы. На практике любой такой параметр можно подменить. Поэтому безопасная валидация — это не «дублирование логики фронта», а отдельный слой защиты, который учитывает и намеренные, и случайные отклонения. Чем лучше вы формализуете ожидания по каждому параметру, тем меньше пространство для SQL‑инъекций, XSS, RCE и других классических атак.
—
Ошибки, которые чаще всего допускают при работе с API в браузере
Неправильное логирование и утечки через консоль
Одна из распространённых недооценённых проблем — логирование чувствительных данных прямо в браузерную консоль. В процессе отладки очень легко добавить `console.log(token)` или полный ответ сервера, где могут присутствовать персональные данные, служебные идентификаторы или диагностические сообщения. Если эти вызовы не убираются перед релизом, то любой пользователь с минимальными знаниями может открыть DevTools и получить доступ к тому, что изначально не предполагалось показывать. А при наличии XSS‑уязвимости вредоносный скрипт легко соберёт всю эту информацию и отправит внешнему злоумышленнику.
Кроме того, даже при отключённых логах в продакшене многие приложения продолжают писать подробные журналы на стороне сервера, включая исходные запросы и заголовки. Если система логирования неправильно защищена или доступ к ней получают лишние сотрудники, возникает вторичный канал утечки. В идеале нужно применять маскирование чувствительных полей, строгие права доступа к логам и ограниченный срок их хранения, сопоставленный с политикой безопасности компании и требованиями регуляторов.
«Временные» дыры, которые живут годами
Ещё одна типичная история: временные обходы или тестовые эндпоинты, которые создавались «на пару дней», а потом благополучно забывались. В спешке релиза разработчики часто оставляют открытые маршруты без авторизации для удобства фронтенд‑тестирования или проверки интеграций. Со временем такие точки входа превращаются в тихие, но очень опасные уязвимости, потому что о них помнит всё меньше людей, а сканеры и злоумышленники находят их через перебиранние маршрутов и анализ структуры приложения.
Чтобы не попадать в такие ловушки, полезно внедрять регулярный аудит безопасности api веб приложений, цена которого окупается предотвращёнными инцидентами и экономией на аварийных патчах. Автоматические сканеры в сочетании с ручным ревью конфигураций помогают выявлять забытые эндпоинты, незащищённые методы и слишком широкие разрешения. Регулярность здесь куда важнее, чем глубина единичной проверки: лучше проводить небольшие аудиты чаще, чем один большой раз в пару лет.
—
Советы для новичков: как не утонуть в безопасности и всё же сделать продукт
1. Начните с нескольких базовых правил
1. Не храните в фронтенде ничего, что нельзя показать пользователю.
2. Всегда проверяйте права на сервере, даже если фронтенд уже отфильтровал интерфейс.
3. Относитесь к каждому параметру запроса как к потенциально вредоносному.
4. Настройте CORS точечно, а не «на все домены сразу».
5. Используйте минимальные возможные полномочия для каждого токена и роли.
Эти простые правила не требуют глубокого погружения в криптографию или сложные стандарты, но уже заметно сокращают число потенциальных дыр. Новичкам важно не пытаться «сделать всё идеально с нуля», а постепенно выстраивать привычки, которые автоматически ведут к более безопасным решениям. Если база заложена правильно, дальнейшее усложнение архитектуры будет менее болезненным, и вы избежите многих типичных ловушек, в которые регулярно попадают начинающие команды.
2. Учитесь на реальных кейсах, а не только по документации
Даже самый подробный мануал не заменит практику и разбор реальных инцидентов. Обратите внимание на курсы по безопасности web api для разработчиков, особенно те, где разбираются популярные уязвимости в формате «вот так делали, вот как сломали и вот как починили». Такой формат обучения лучше запоминается и формирует практическое чувство опасности: вы начинаете заранее замечать подозрительные места в архитектуре и коде. Документация же часто описывает «идеальный мир», который в реальных проектах встречается нечасто.
Полезно также периодически просматривать отчёты о взломах и публичные постмортемы компаний, которые открыто рассказывают, как их атаковали. В таких текстах хорошо видна связь между, казалось бы, мелочами (лишний эндпоинт, слишком подробное сообщение об ошибке, неочищенный тестовый ключ) и серьёзными последствиями. Этот опыт сложно воспроизвести в учебной среде, но он отлично дополняет теорию и даёт мотивацию внедрять защитные практики на ранних этапах.
3. Не бойтесь просить помощи и внешнего взгляда

Даже если в команде есть опытные разработчики, взгляд со стороны оказывается полезен. Периодические ревью архитектуры и кода сторонними специалистами помогают поймать системные проблемы, которые уже стали «фоновым шумом» для внутренних участников. Иногда достаточно одной консультации по безопасной интеграции api в frontend, чтобы скорректировать несколько ключевых решений и существенно снизить риск. Особенно это актуально для проектов, которые выходят в продакшен под высокой нагрузкой или работают с персональными и финансовыми данными.
Если в компании нет выделенного специалиста по безопасности, можно использовать внешние услуги аудиторов или консультантов, но выбирать их стоит осознанно: по кейсам, отзывам и реальной экспертизе в вашей стек‑среде. Разовые проверки перед большим релизом и последующее внедрение рекомендаций дают хороший баланс между затратами и эффектом. Постепенно вы сможете перенять практики и встроить их в свой стандарт разработки, уменьшая зависимость от внешних подрядчиков.
—
Как связать всё вместе: практичная стратегия для повседневной разработки
Комбинируем подходы, а не выбираем «единственно верный»
На практике редко работает абсолютный подход «только прямой доступ к API» или «только через прокси‑слой». Чаще всего разумная архитектура использует смесь обоих вариантов: часть публичных, малочувствительных операций можно отдавать напрямую в браузер, тщательно ограничив права и валидацию; более критичные сценарии — прятать за бэкенд‑шлюзом с дополнительными проверками. Такой гибрид помогает сохранить производительность и простоту разработки, не жертвуя при этом здравым уровнем безопасности.
Важно, чтобы это комбинирование было осознанным и задокументированным. Для каждого эндпоинта нужно понимать, почему он доступен из браузера напрямую или через прокси, какие риски это создаёт и как они компенсируются. Тогда при изменении требований, росте нагрузки или появлении новых регуляторных норм не придётся «перестраивать дом по кирпичику», а можно будет целенаправленно усиливать только уязвимые компоненты. Со временем такой подход превращается в практический навык, и команда уже автоматически закладывает в дизайн сервисов параметры безопасности как часть функционала, а не отдельный блок, о котором вспоминают перед запуском.
Если проект растёт и становится критичным для бизнеса, имеет смысл рассмотреть не только точечные меры, но и системный внешний аудит, периодические пентесты и внутренние регламенты по работе с секретами. На этом этапе полезны как внутренние тренинги, так и формальные услуги по защите и тестированию api в браузере от специализированных команд. В долгосрочной перспективе это дешевле, чем разбираться с последствиями успешной атаки и восстановлением доверия пользователей, поэтому разумный баланс между безопасностью и скоростью разработки — не абстрактная теория, а прямое конкурентное преимущество.
Комментарии